SpaRRTa
Spatial Relation Recognition Task
A Synthetic Benchmark for Evaluating Spatial Intelligence in Visual Foundation Models


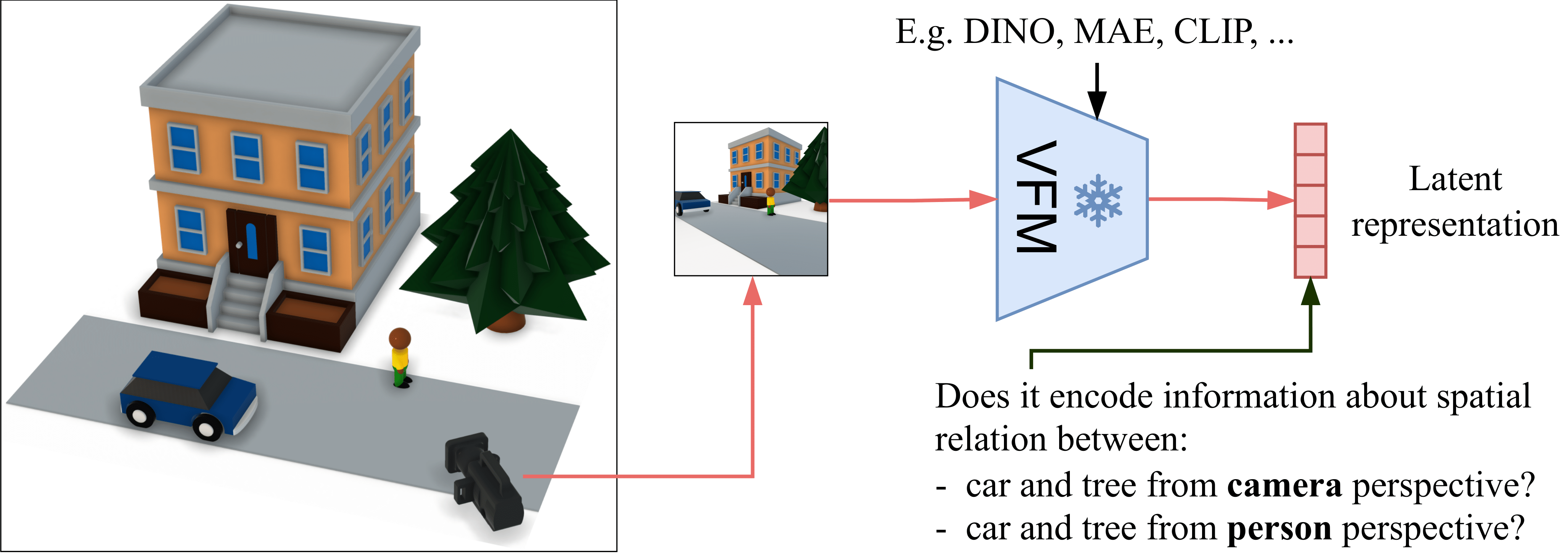
Abstract¶
Visual Foundation Models (VFMs), such as DINO and CLIP, exhibit strong semantic understanding but show limited spatial reasoning capabilities, which limits their applicability to embodied systems. Recent work incorporates 3D tasks (such as depth estimation) into VFM training. However, VFM performance remains inconsistent across different tasks, raising the question: do these models truly have spatial awareness or overfit to specific 3D objectives?
To address this question, we introduce the Spatial Relation Recognition Task (SpaRRTa) benchmark, which evaluates the representations of relative positions of objects across different viewpoints. SpaRRTa can generate an arbitrary number of photorealistic images with diverse scenes and fully controllable object arrangements, along with freely accessible spatial annotations.
Key Statistics¶
Key Findings¶
Main Results
-
Spatial information is patch-level: Spatial relations are primarily encoded at the patch level and largely obscured by global pooling
-
3D supervision enriches patch features: VGGT (3D-supervised) shows improvements only with selective probing, not linear probing
-
Allocentric reasoning is challenging: All models struggle with perspective-taking tasks compared to egocentric variants
-
Environment complexity matters: Performance degrades significantly in cluttered environments like City scenes
Environments¶




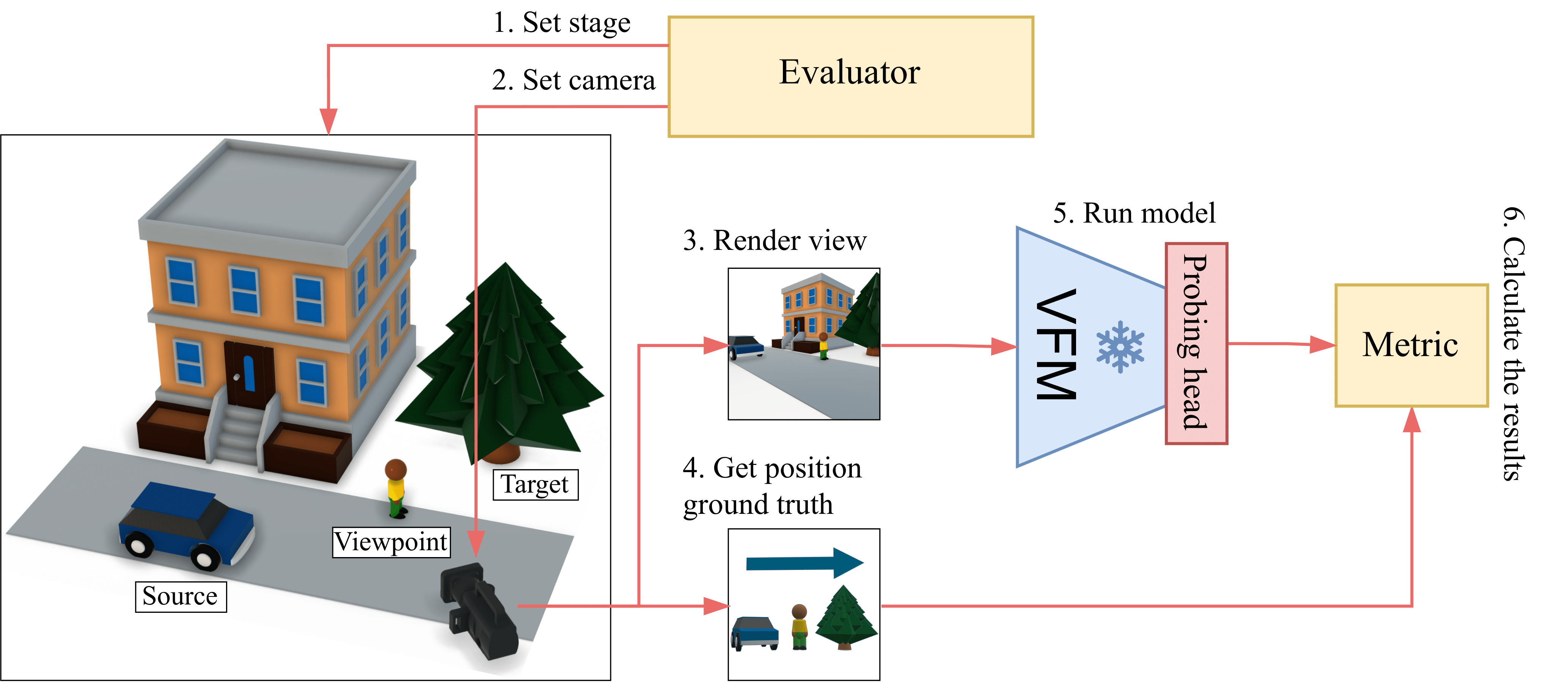
Evaluation Pipeline¶
Authors¶
Affiliations¶




Citation¶
If you find SpaRRTa useful in your research, please cite our paper:
@misc{kargin2026sparrta,
title={SpaRRTa: A Synthetic Benchmark for Evaluating Spatial Intelligence in Visual Foundation Models},
author={Turhan Can Kargin and Wojciech Jasiński and Adam Pardyl and Bartosz Zieliński and Marcin Przewięźlikowski},
year={2026},
eprint={2601.11729},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2601.11729}
}Acknowledgments¶
This research has been supported by the flagship project entitled “Artificial Intelligence Computing Center Core Facility” from the Priority Research Area DigiWorld under the Strategic Programme Excellence Initiative at the Jagiellonian University. The work of Turhan Can Kargin, Adam Pardyl, and Bartosz Zieliński was supported by National Science Centre (Poland) grant number 2023/50/E/ST6/00469. The research of Marcin Przewięźlikowski was supported by the National Science Centre (Poland), grant no. 2023/49/N/ST6/03268. We gratefully acknowledge Polish high-performance computing infrastructure PLGrid (HPC Center: ACK Cyfronet AGH) for providing computer facilities and support within computational grant no. PLG/2025/018312.