Evaluation of Visual Foundation Models¶
SpaRRTa provides a systematic methodology for evaluating how Visual Foundation Models (VFMs) encode and represent spatial relations between objects.
The Spatial Relation Recognition Task¶
The core task is to determine the relative spatial relation between two objects in an image:
- Source Object: The reference point for the spatial relation
- Target Object: The object whose position is being queried
- Viewpoint: The perspective from which the relation is evaluated
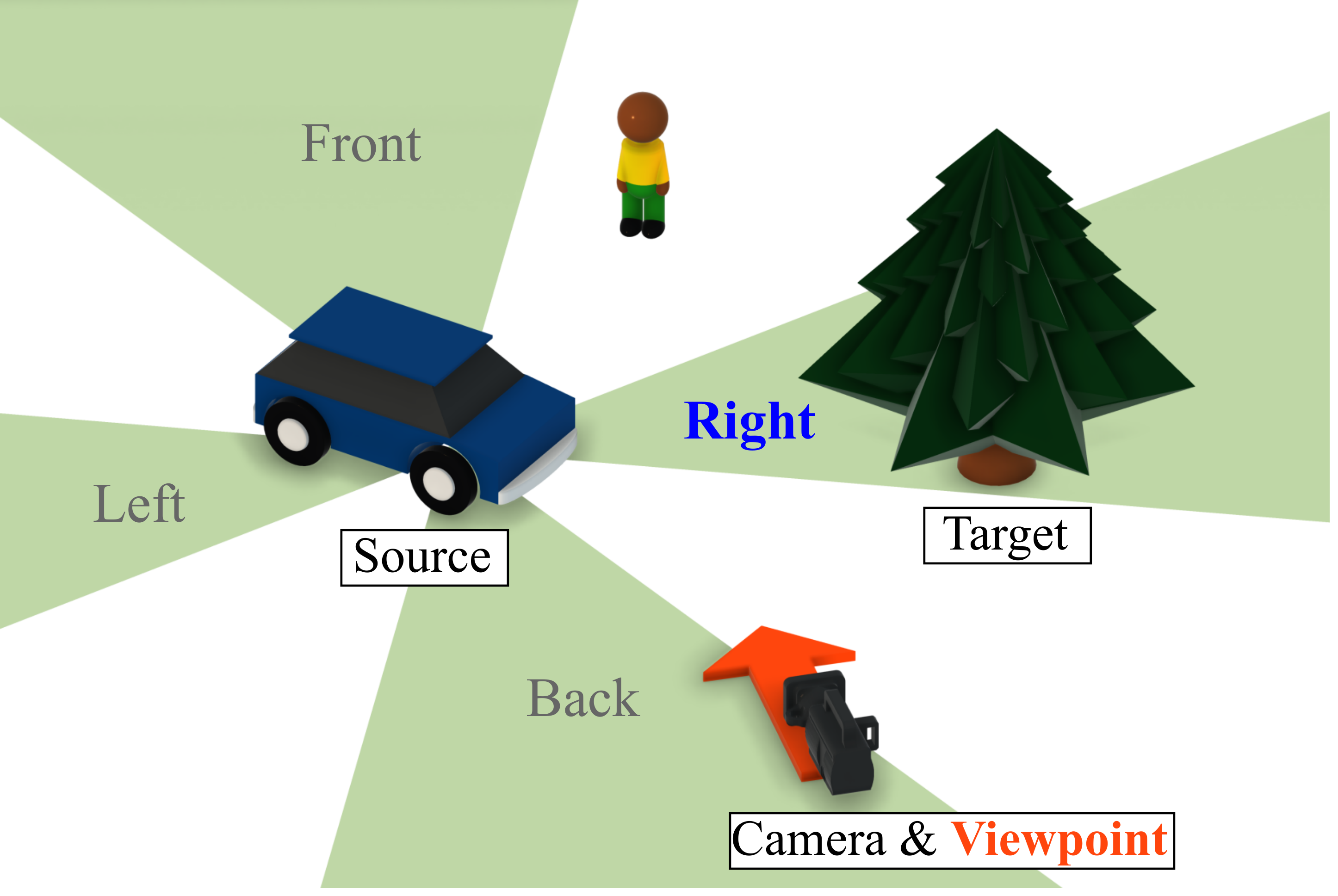
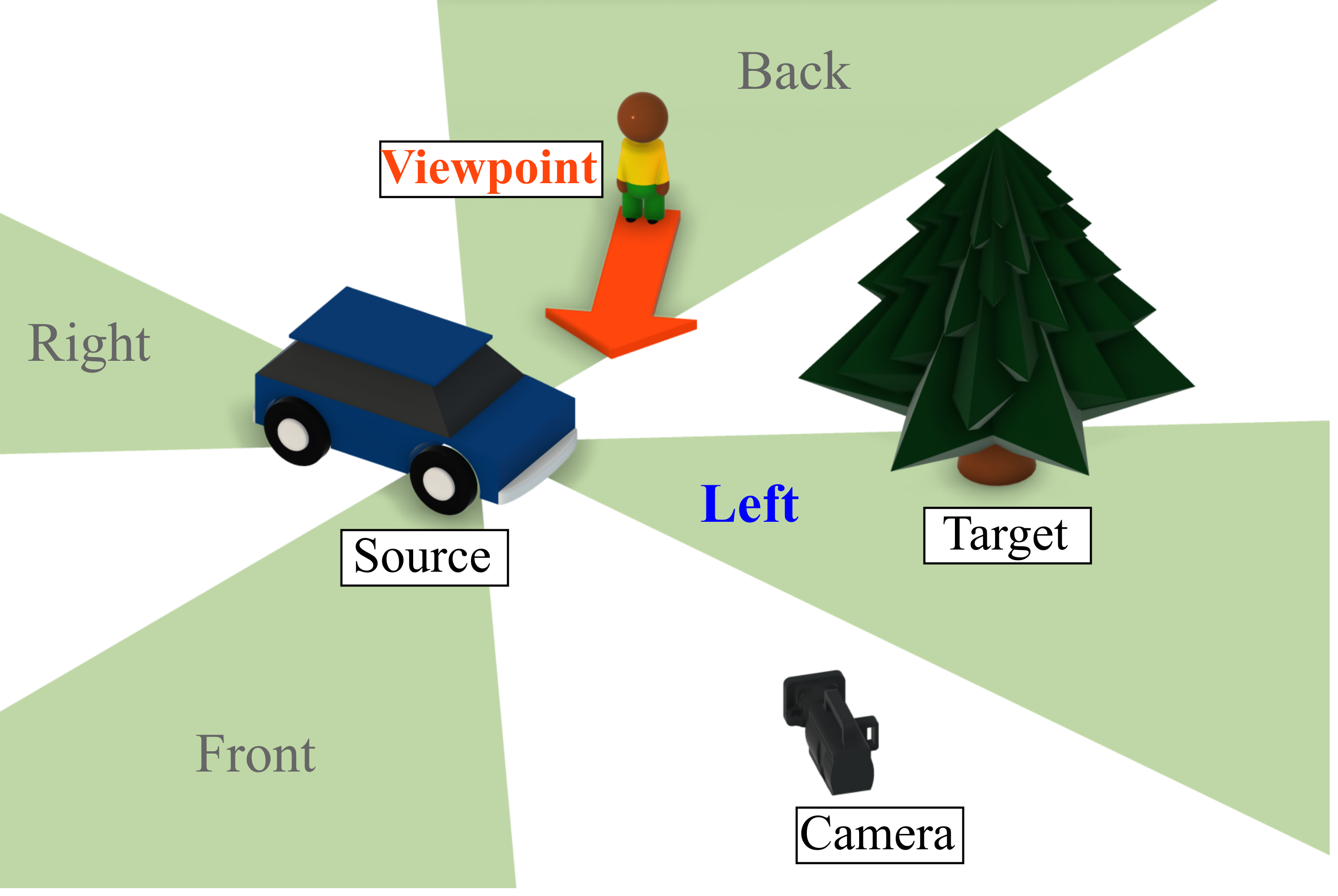
Left: Egocentric task (camera viewpoint). Right: Allocentric task (human viewpoint).
Task Variants¶
The camera defines the viewpoint for spatial relations.
Example Query
"Where is the tree (target) relative to the car (source) from the camera's perspective?"
Characteristics:
- Directly observable from input image
- Simpler—no perspective transformation needed
- Tests basic spatial layout understanding
Answer: The relation as seen from the camera (Front/Back/Left/Right)
A third object (human) defines the viewpoint for spatial relations.
Example Query
"Where is the tree (target) relative to the car (source) from the human's perspective?"
Characteristics:
- Requires implicit perspective transformation
- More challenging—must reason from another viewpoint
- Tests abstract spatial reasoning capability
Answer: The relation as would be seen from the human's position
Classification Labels¶
The task is formulated as a 4-way classification:
| Label | Description |
|---|---|
| Front | Target is in front of source (from viewpoint) |
| Back | Target is behind source (from viewpoint) |
| Left | Target is to the left of source (from viewpoint) |
| Right | Target is to the right of source (from viewpoint) |
Evaluated Models¶
We evaluate a diverse suite of VFMs spanning different learning paradigms:
Joint-Embedding Architectures (JEA)¶
| Model | Backbone | Pre-training | Dataset |
|---|---|---|---|
| DINO | ViT-B/16 | Contrastive / Distillation | ImageNet-1k |
| DINO-v2 | ViT-B/14 | DINO + iBOT | LVD-142M |
| DINO-v2 (+reg) | ViT-B/14, ViT-L/14 | DINO-v2 w/ Register Tokens | LVD-142M |
| DINOv3 | ViT-B/16 | DINO + iBOT | LVD-1689M |
Masked Image Modeling (MIM)¶
| Model | Backbone | Pre-training | Dataset |
|---|---|---|---|
| MAE | ViT-B/16 | Pixel Reconstruction | ImageNet-1k |
| MaskFeat | ViT-B/16 | HOG Feature Prediction | ImageNet-1k |
| SPA | ViT-B/16 | Masked Volumetric Neural Rendering | ScanNet, Hypersim, S3DIS |
| CroCo | ViT-B/16 | Cross-View Completion | Habitat |
| CroCov2 | ViT-B/16 | Cross-View Completion | ARKitScenes, MegaDepth, ... |
Supervised & Weakly Supervised¶
| Model | Backbone | Pre-training | Dataset |
|---|---|---|---|
| VGGT | ViT-L/14 | Multi-Task 3D Regression | Co3D, MegaDepth, etc. |
| DeiT | ViT-B/16 | Classification + Distillation | ImageNet-1k |
| CLIP | ViT-B/16 | Image-Text Contrastive | Web Image-Text (WIT) |
Interactive Prediction Demo¶
Explore spatial relation predictions from the VGGT model using our interactive demo. Efficient Probing is used for prediction. Attention maps of efficient probing heads are visualized to show which regions of the image the model is paying attention to. Select an environment and viewpoint to see how the model predicts spatial relations between objects.

Reference Object: Tree
Target Object: Car
💡 Hover over the images to see objects relationships!
Probing Methodology¶
We evaluate frozen VFM representations using lightweight probing heads:
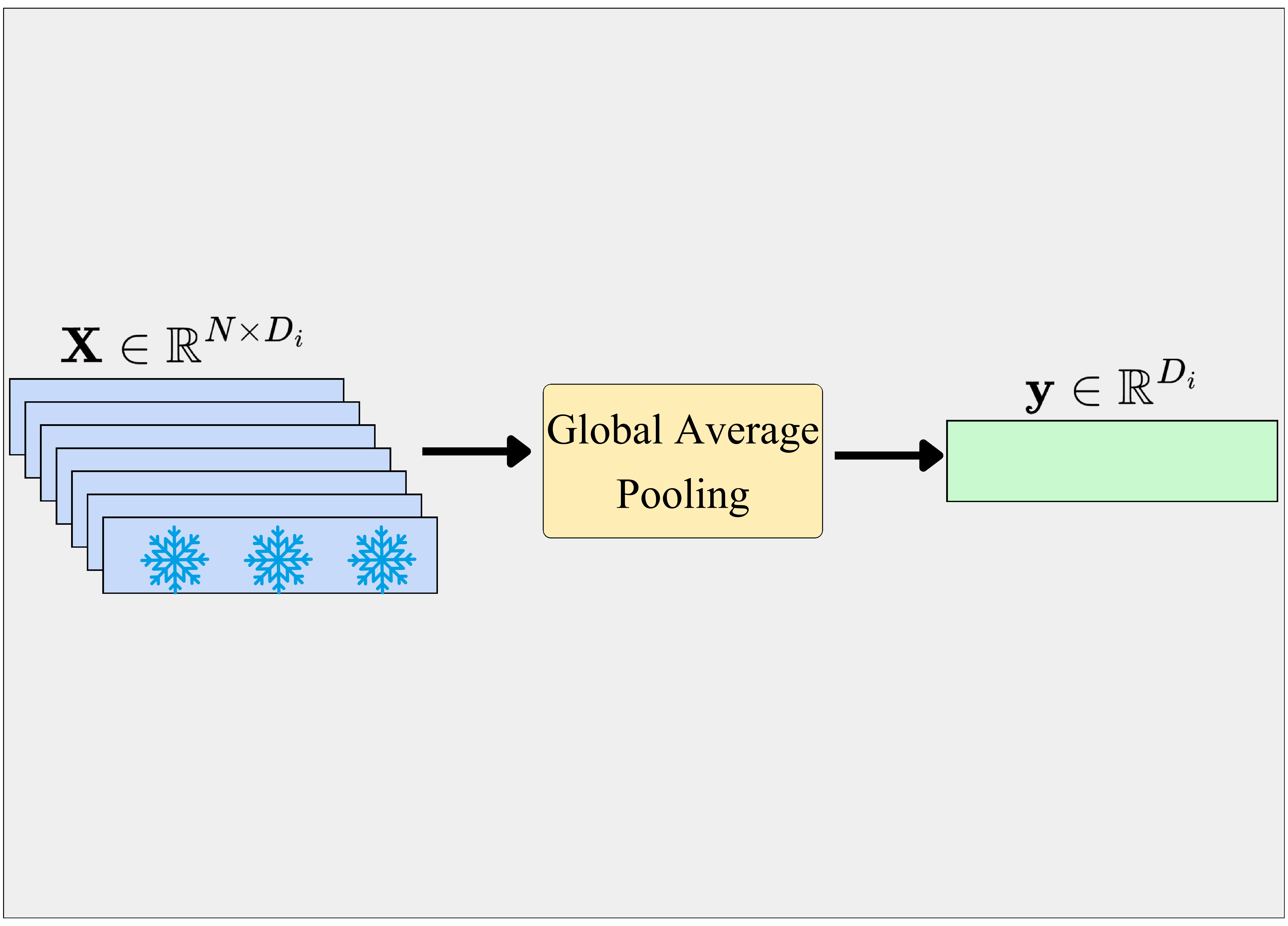
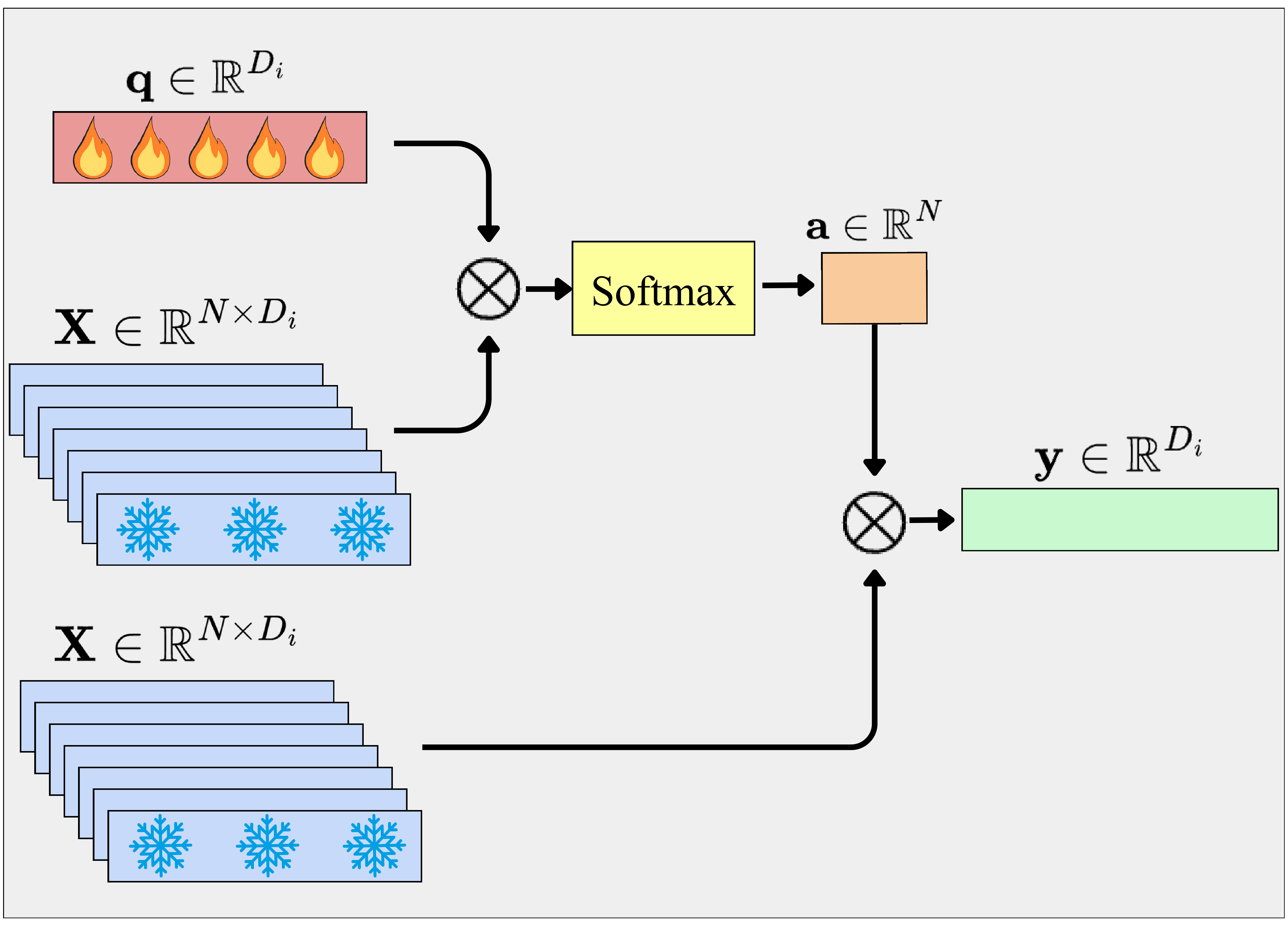
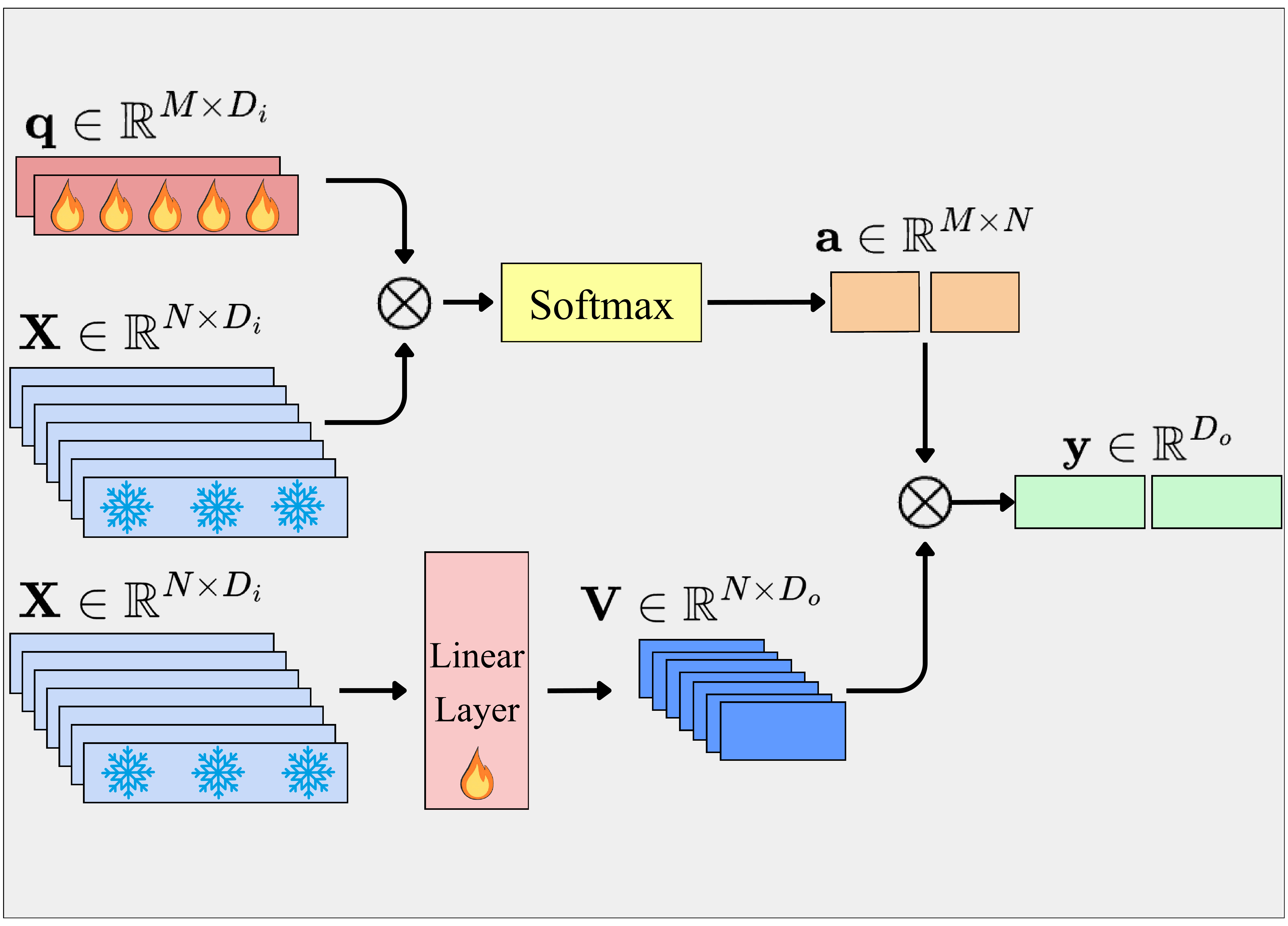
Three probing strategies: Linear Probing with GAP, AbMILP, and Efficient Probing.
Probing Strategies¶
Global Average Pooling + Linear Classifier
dataloader = DataLoader(dataset, batch_size=batch_size)
for images in dataloader:
features = vfm.forward_features(images) # [Batch_size, Num_patches, Dimension]
global_feat = features.mean(dim=1) # [Batch_size, Dimension]
prediction = linear_layer(global_feat) # [Batch_size, 4]
Pros: Simple baseline, standard evaluation protocol
Cons: Treats all patches equally, loses local spatial information
Attention-Based Multiple Instance Learning Pooling
dataloader = DataLoader(dataset, batch_size=batch_size)
for images in dataloader:
features = vfm.forward_features(images) # [Batch_size, Num_patches, Dimension]
attn_map = linear_layer(features, 1) # [Batch_size, Num_patches, 1]
attn_map = softmax(attn_map, dim=1) # [Batch_size, Num_patches, 1]
weighted_feat = (attn_map * features).sum(dim=1) # [Batch_size, Dimension]
prediction = linear_layer(weighted_feat) # [Batch_size, 4]
Pros: Learns to focus on relevant patches
Cons: Single attention map may not capture multiple objects
Multi-Query Cross-Attention
dataloader = DataLoader(dataset, batch_size=batch_size)
queries = Parameter(torch.randn(1, num_queries, dimension) * 0.02) # [1, Num_queries, Dimension]
values = linear_layer(dimension, (dimension/d_out)/num_queries)
for images in dataloader:
features = vfm.forward_features(images) # [Batch_size, Num_patches, Dimension]
attn_map = queries @ features.transpose(-2, -1) # [Batch_size, Num_queries, Num_patches]
attn_map = softmax(attn_map, dim=-1) # [Batch_size, Num_queries, Num_patches]
weighted_feat = matmul(attn_map, values) # [Batch_size, Num_queries, (Dimension/d_out)/Num_queries]
weighted_feat = weighted_feat.view(Batch_size, -1) # [Batch_size, Dimension/d_out]
prediction = linear_layer(weighted_feat) # [Batch_size, 4]
Pros: Multiple queries can specialize to different objects/regions
Cons: More parameters, may overfit on small datasets
Hyperparameters¶
| Parameter | Linear | AbMILP | Efficient |
|---|---|---|---|
| Optimizer | AdamW | AdamW | AdamW |
| Scheduler | Cosine Decay | Cosine Decay | Cosine Decay |
| Learning Rate | 1e-2, 1e-3, 1e-4 | 1e-2, 1e-3, 1e-4 | 1e-2, 1e-3, 1e-4 |
| Weight Decay | 0.001 | 0.001 | 0.001 |
| Dropout | 0.2, 0.4, 0.6 | 0.2, 0.4, 0.6 | 0.2, 0.4, 0.6 |
| Batch Size | 256 | 256 | 256 |
| Epochs | 1000 | 500 | 500 |
| Warmup Steps | 200 | 100 | 100 |
| Queries (num_queries) | - | - | 4 |
| Output Dimension (d_out) | D_i | D_i | D_i/8 |
Evaluation Protocol¶
Data Splits¶
For each environment and object triple:
- Training: 80%
- Validation: 10% (hyperparameter selection)
- Test: 10% (final evaluation)
Metrics¶
- Accuracy: Primary metric (4-way classification)
- Mean Rank: Model ranking across environments/tasks
- Per-Environment Accuracy: Fine-grained analysis
Reproducibility¶
- Random Seeds: 2 seeds per experiment
- Object Triples: 3 distinct triples per environment
- Cross-Validation: Validation set for best checkpoint selection
Key Insights¶
Performance Hierarchy¶
graph LR
A[Linear Probing] -->|"worse than"| B[AbMILP]
B -->|"worse than"| C[Efficient Probing]
style A fill:#ff6b6b,color:#fff
style B fill:#4a90e2,color:#fff
style C fill:#1dd1a1,color:#fffMain Finding
Spatial information is primarily encoded at the patch level and is largely obscured by global pooling. Selective probing mechanisms (AbMILP, Efficient Probing) consistently outperform linear probing.
Model Rankings¶
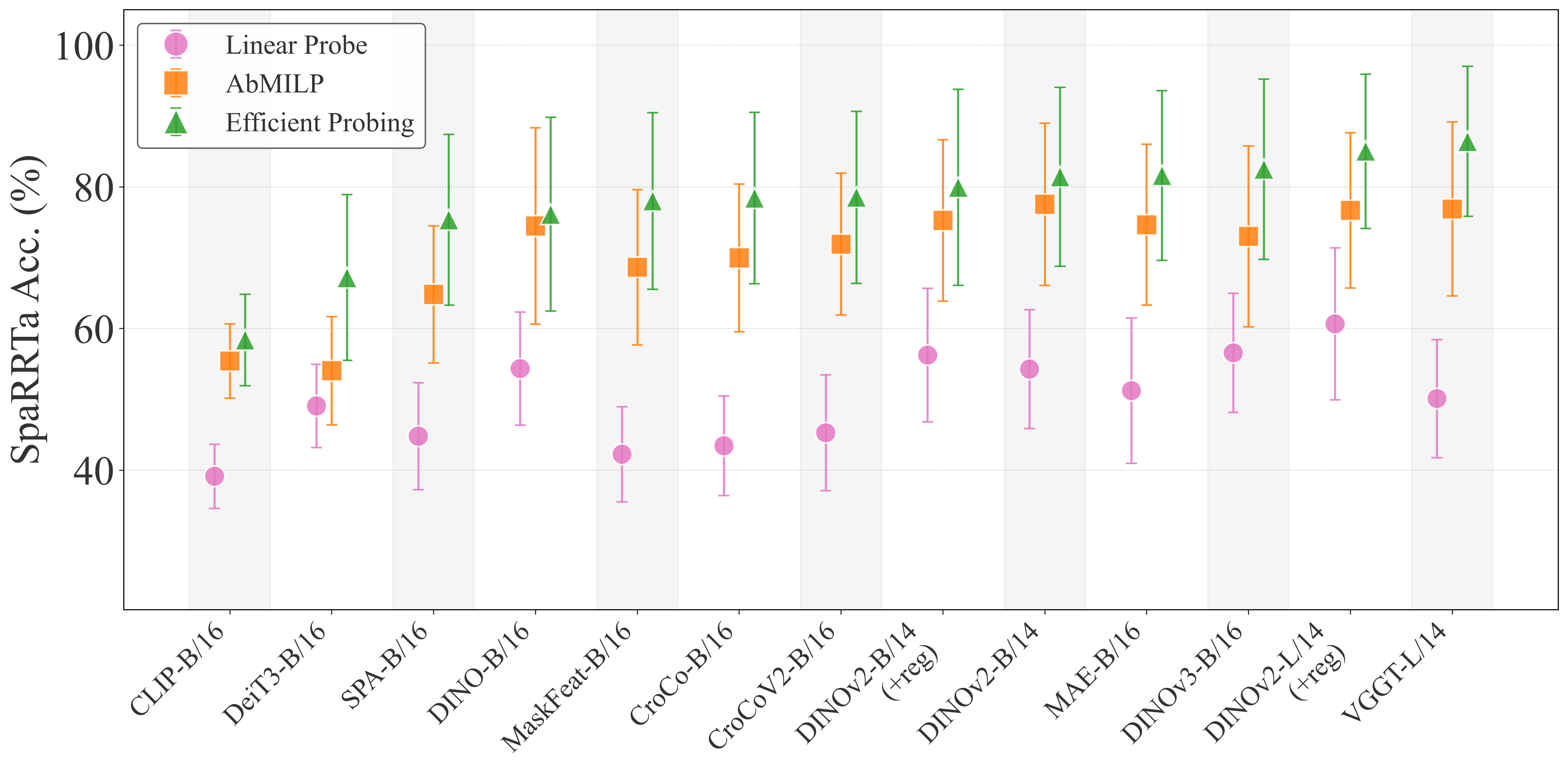
Top Performers:
- VGGT (with Efficient Probing) - Best overall spatial reasoning
- DINO-v2 (+reg) ViT-L - Strong across all probing methods
- DINOv3 - Best ViT-B model with Efficient Probing
- MAE - Surprisingly strong performance
Underperformers:
- CLIP and DeiT - Limited spatial awareness, their semantic features don't transfer to spatial tasks
Task Difficulty¶
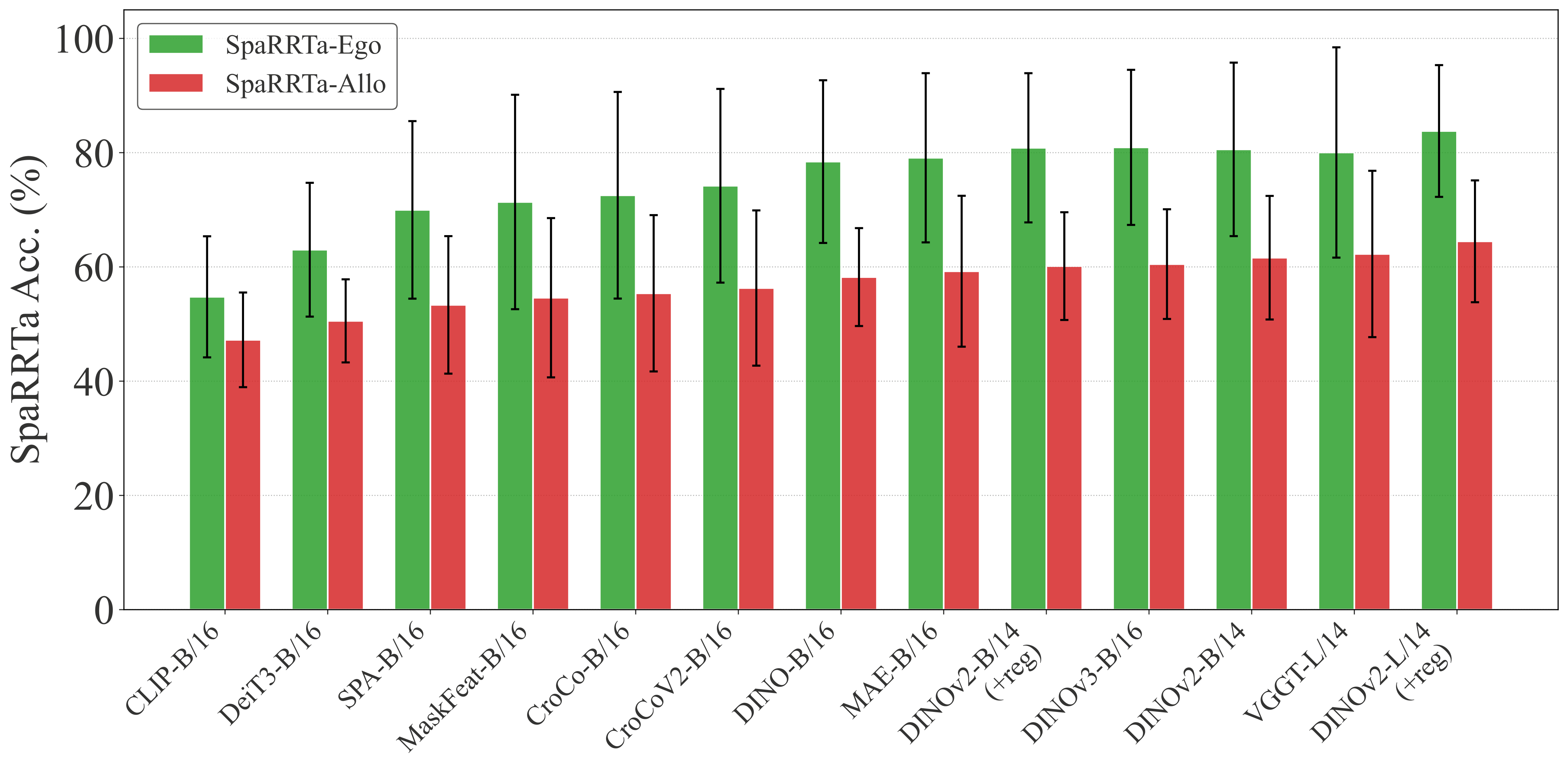
Allocentric Challenge
All models show significant performance drops on allocentric tasks compared to egocentric. This indicates that perspective-taking remains a fundamental challenge for current VFMs.